
礙於篇幅緣故,過多細節的部分,會挑重點講述,如有疑問歡迎留言討論
在上一篇 Day 15 我們提到如何使用我們的 zsh terminal plugin,
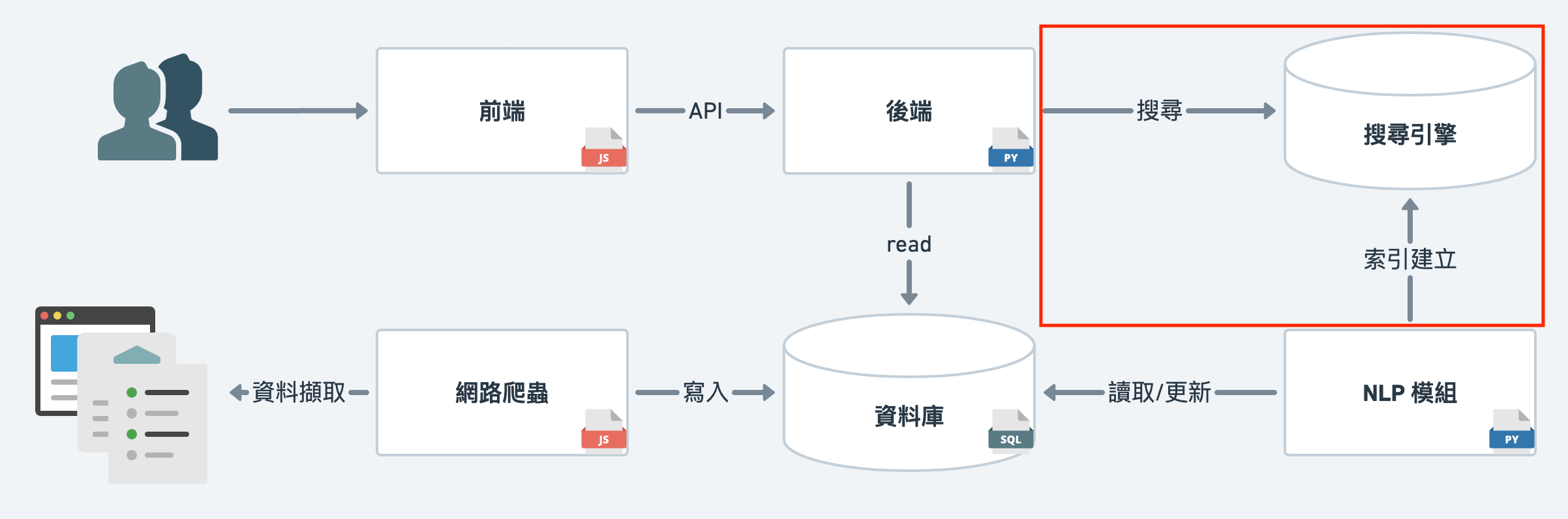
今天我們會進入搜尋引擎的部分,
我們使用 meilisearch 架設這次搜尋引擎伺服器。
為了能滿足搜尋的服務,我們必須要建立索引,
除此之外,根據功能需求,我們還要調整設定。
接下來,我們會花 3 天的時間來介紹
索引
索引時,要存入哪些資料?索引?搜尋
meilisearch 搜尋與排序的背後邏輯其他功能實作
Auto Complete 與 Highlight
在開始設計實作前,
我們必須了解實作的功能需求、想要解決的問題。
清點一下這次實作的基本功能包含
Auto Complete (也稱 Auto Fill)Search
Highlight
Search 是必要的功能,想來也無須贅述。
除此之外,Auto Complete 與 Highlight 我們在 Day 05 也以 google 為例,
講述了 Auto Complete 是為了幫助使用者更好的組織語言,
將關鍵字表達得更加具體、詳細,以利搜尋引擎提供更加精確的結果。
而 Highlight 則是為了管理使用者的專注,並強調結果內容中的某部分。
在了釐清我們要實作的功能後,
我們接下來會介紹 Index (索引), Schema, and Settings (設定)。
在 Day 03 中我們介紹,為何必須要建立索引。
除此之外,在接下來建立索引前,我們有些觀念必須釐清。
我們並 不是 把所有的資料都從資料庫複製到搜尋引擎,
同時,我們也 不是 把搜尋引擎當成資料庫。
通常我們會將原始的資料存在資料庫中,
而搜尋引擎則會根據功能需求,思考
因此,我們 Day 11 ~ Day 14 中所介紹的資料處理內容,
其實就是從資料庫將原始資料讀取出來,
根據需求加工成搜尋引擎所需要的格式與內容。
將初始資料與加工後的資料分開存放的另一個好處還有,
今天如果功能上需要更新,
或是我們有新的資料處理步驟、方法時,
我們還保留原始資料,
並不需要從爬所有資料再做資料處理。
Schema 在其他的 搜尋引擎 如:elasticsearch 中,
在建立索引前,便需要準備好,
Schema 等同告訴搜尋引擎我們會有哪些的資料存入索引,
也就是索引中的 field (值),且這些 field 的資料格式為何?
然而,meiliesearch相對簡化的一點便是schemaless。
雖然我們因此不需要準備schema,
但我們還是要知道我們要用到哪些資料,
因此,我在 github repo 中還是留下了 doc search schema reference 以供參考。
它像是一個設定檔,用來設定索引,
並會影響後續在此索引上搜尋時的一些設定。
如:可以設定哪些 fields 可以在搜尋時被使用,
哪些字詞在搜尋時應被視為同義詞等等。
我們在明天的章節會根據實作需求進一步介紹。
設定檔在 doc search settings 也可瀏覽。
明天我們會就第二部分,search的實作繼續介紹。

 iThome鐵人賽
iThome鐵人賽